Skip to content
CTERA Recognized as Strong Performer on Gartner® Peer Insights™
Read Press Release
CTERA Erases the Boundary Between File and Object
Read Press Release
Contact CTERA
Support
Careers
Platform
CTERA Intelligent Data Platform
Architecture
A Unified Data Fabric for the Enterprise
Deployment Models
Your Infrastructure, Your Choice of Service
Data Migration
Seamlessly Transition from Legacy Systems
Security, Compliance, & Resilience
Protection, Governance, and Ransomware Defense
Integration & APIs
Connect and Automate Your Enterprise Ecosystem
Enterprise Data Services
Cyber Protection
Multi-Layered Ransomware Defense and Data Protection
CTERA Insight
Global Data Analytics and Intelligence
CTERA Global File Locking
Centralized File Locking for Distributed Teams
Enterprise Content & AI Services
CTERA Search
Enterprise-Secure Search for Your Files
CTERA Classify
Automated Data Classification and Governance in Real Time
CTERA Experts
Secure, Trustworthy AI for Your Enterprise Data
Solutions
Solutions by Role
For Cloud Leaders
For Data Leaders
For Security Teams
For IT Leaders
Solutions by Challenge
NAS Modernization
Remote Workforce Enablement
Ransomware Protection
Compliance & Governance
Data Classification & Visibility
AI & Analytics Readiness
Solutions by Industry
AEC
Financial Services
Government & Defense
Healthcare
Legal Services
Manufacturing
Oil & Gas
Other
Partners
Find Partners
Channel Partners
Alliance Partners
Technology Partners
Partner Resources
Become a Partner
Partner Portal
Blogs
Resources
Resource Hub
Grow your knowledge with webinars, videos, whitepapers and case studies
Blogs
Latest news, insights and tips from our expert professionals
TCO Calculator
Calculate the infrastructure cost savings offered by CTERA in comparison to other file storage alternatives
CTERA Training
On-demand learning courses and hands-on practical training
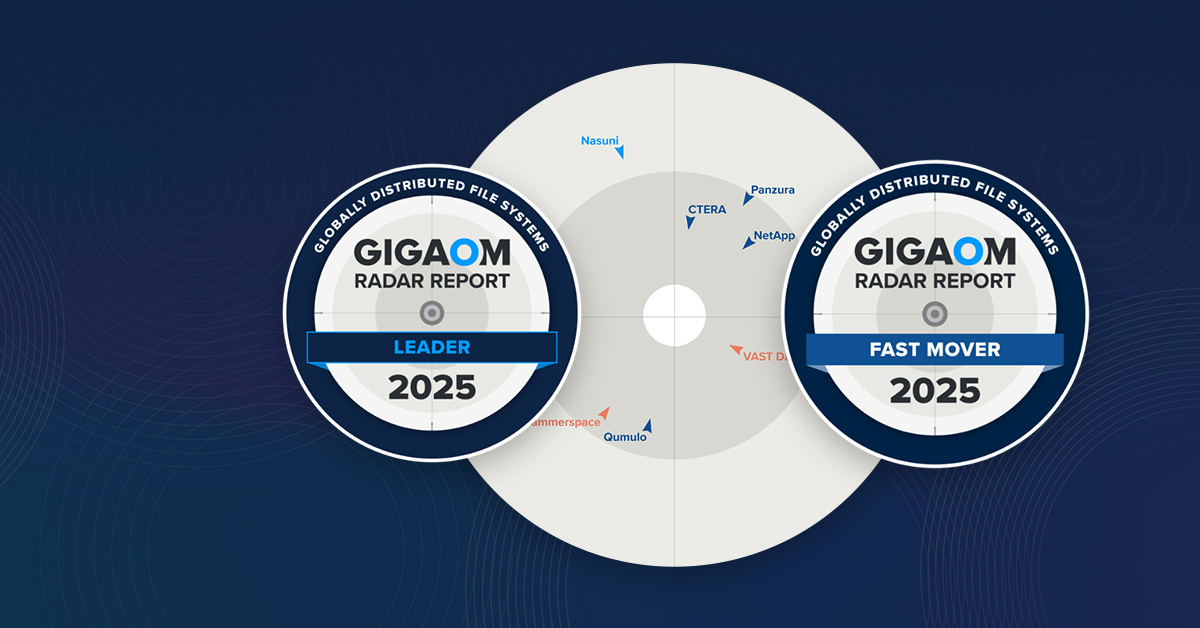
GigaOm Radar for Globally Distributed File Systems 2025
View Report
TCO Calculator:
Save
80%
on
your storage costs
Learn More
Company
About CTERA
Leadership Team
Events
Newsroom
Press Release:
CTERA Reaffirms Its Position as a Market Leader in AI-Driven Hybrid Cloud File Services
Read More
Blog: Introducing CTERA Data Intelligence
Read
Platform
CTERA Intelligent Data Platform
Architecture
Deployment Models
Data Migration
Security, Compliance, & Resilience
Integration & APIs
Enterprise Data Services
Cyber Protection
CTERA Insight
CTERA Global File Locking
Enterprise Content & AI Services
CTERA Search
CTERA Classify
CTERA Experts
Solutions
Solutions by Role
For Cloud Leaders
For Data Leaders
For Security Teams
For IT Leaders
Solutions by Challenge
NAS Modernization
Remote Workforce Enablement
Ransomware Protection
Compliance & Governance
Data Classification & Visibility
AI & Analytics Readiness
Solutions by Industry
Architecture, Engineering, and Construction
Financial Services
Government and Defense
Healthcare
Legal Services
Manufacturing
Oil & Gas
Other Industries
Partners
Find Partners
Channel Partners
Alliance Partners
Technology Partners
Partner Resources
Become a Partner
Partner Portal
Resources
Resource Hub
Blogs
TCO Calculator
CTERA Training
Company
About CTERA
Leadership Team
Events
Newsroom
Contact CTERA
Support
Blog
Get a Demo
Product Tour
Blog | By Oded Nagel
Federated Architecture: The Key to a Unified Data Fabric and AI Workloads
CTERA unifies file and object domains without compromising on performance, budget or control
Read Now
Blog | By Oded Nagel
Frost & Sullivan Recognizes CTERA's Leadership Role in Hybrid Cloud Storage
Military-Grade Security Meets Lightning-Fast Data Transfer: The CTERA Advantage
Read Now
Blog | By Mike Ivanov
Leading the Pack: How CTERA Stands Out in GigaOm’s 2025 Radar
The report offers leaders a guide to navigate the rapidly-changing data landscape
Read Now
Blog
|
Julian Weiss
April 14, 2026
Who Needs Direct Access to Their Data?
Read Now
Blog
|
Robin Stone
March 26, 2026
CTERA Recognized as a 2025 Strong Performer for Hybrid Cloud Storage on Gartner® Peer Insights™
Read Now
Blog
|
Oded Nagel
March 11, 2026
Federated Architecture: The Key to a Unified Data Fabric and AI Workloads
Read Now
Blog
|
Aron Brand
March 11, 2026
File and Object Storage Convergence: The Missing Foundation for Enterprise AI
Read Now
Blog
|
Justin Flynn
March 5, 2026
Lessons from the Field: The Value of a Technical Account Manager
Read Now
Blog
|
Ravit Sadeh
March 3, 2026
Enterprise AI Integration: What We Learned Embedding MCP Into CTERA’s Platform
Read Now
Blog
|
Aron Brand
February 9, 2026
Stop Paying SSD Prices for Cold Data
Read Now
Blog
|
Oded Nagel
February 5, 2026
Is Your Data Ready for a New Job?
Read Now
Blog
|
Mike Ivanov
January 15, 2026
CTERA Named as a File Storage Leader for Third Consecutive Year by Coldago Research
Read Now
Blog
|
Aron Brand
January 13, 2026
We’re Confiding in Machines. That Should Make Us Pause
Read Now
Blog
|
Kyle Edsall
January 6, 2026
Multi-Cloud Resilience: Why Cloud Outages Are a Data Strategy Problem, Not a Provider Problem
Read Now
Blog
|
Alex Berman
December 18, 2025
Secure File Collection with Upload-Only Links: 9 Powerful Wins
Read Now
<
Page
1
Page
2
Page
3
…
Page
14
>
Categories
Blog
(77)
Company News
(26)
General
(10)
Insight
(42)
Product News
(12)
Product Tips
(5)
Authors
Aron Brand
(55)
Mike Ivanov
(22)
Oded Nagel
(14)
Kyle Edsall
(10)
Ravit Sadeh
(8)
CTERA Networks
(9)
Saimon Michelson
(5)
Alex Berman
(5)
Julian Weiss
(4)
Guest Author
(3)
Shlomi Ako
(2)
Justin Flynn
(2)
Shira Hayon
(2)
James Sadov
(2)
Cheryle Cushion
(2)
Mickael Benchetrit
(1)
Michael Amselem
(1)
Joe Scott
(1)
Robin Stone
(1)
Shai Zur
(1)
Gal Yosef
(1)
Tal Moshe
(1)
Dana Racine
(1)
Amir Goldstein
(1)